




NVIDIA GTC 2026 Keynote: Every Big Announcement Explained
- Author: Saptarshi Chowdhury, Software Developer & Data Analyst | Oracle Cloud Infrastructure 2025 AI Foundations Associate · Google Vertex AI Prompt Design · Deloitte Data Analytics | Founder & Lead Writer, Bloxstation Last Updated: March 20, 2026
Table of Contents
- What Is NVIDIA GTC 2026?
- Vera Rubin: The New AI Supercomputer
- Groq 3 LPU: NVIDIA’s New Inference Chip
- Feynman: A Sneak Peek at 2028’s GPU
- DLSS 5: What It Means for Gamers
- Agentic AI: NemoClaw, OpenClaw, and the Agent Shift
- Self-Driving Cars and Robotics
- The $1 Trillion Outlook
- FAQ
- Conclusion
What Is NVIDIA GTC 2026?
- NVIDIA GTC: the GPU Technology Conference is where CEO Jensen Huang tells the world what comes next in AI hardware, software, and computing. Think Apple’s WWDC, but instead of iPhones, NVIDIA builds the machines that run most of the world’s AI.
- GTC 2026 ran March 16 – 19 at the SAP Centre in San Jose. Around 10,000 people showed up in person. Millions more watched online.
- It was the biggest GTC yet. Seventeen press releases dropped in a single day. Jensen’s two hours keynote covered next generation chips, space based data centres, and yes, a robot version of Olaf from Frozen walking onstage. If you missed it, or watched and still feel confused, this guide covers everything in plain English.
- Here is what NVIDIA announced:
- A new AI computing platform called Vera Rubin (7 new chips, shipping in 2026)
- The Groq 3 LPU, a new inference chip born from its $20 billion acquisition
- A preview of Feynman, the next gen GPU arriving in 2028
- DLSS 5, a major graphics upgrade for PC gamers
- NemoClaw, an enterprise grade agentic AI framework
- New autonomous vehicle partners: BYD, Hyundai, Nissan, and Geely
- A $1 trillion demand signal for AI computing through 2027
- Let us break each one down.

- [IMAGE: Jensen Huang on stage at SAP Center, San Jose, during GTC 2026 keynote — alt: Jensen Huang NVIDIA GTC 2026 keynote]
Vera Rubin: NVIDIA’s New AI Supercomputer, Explained
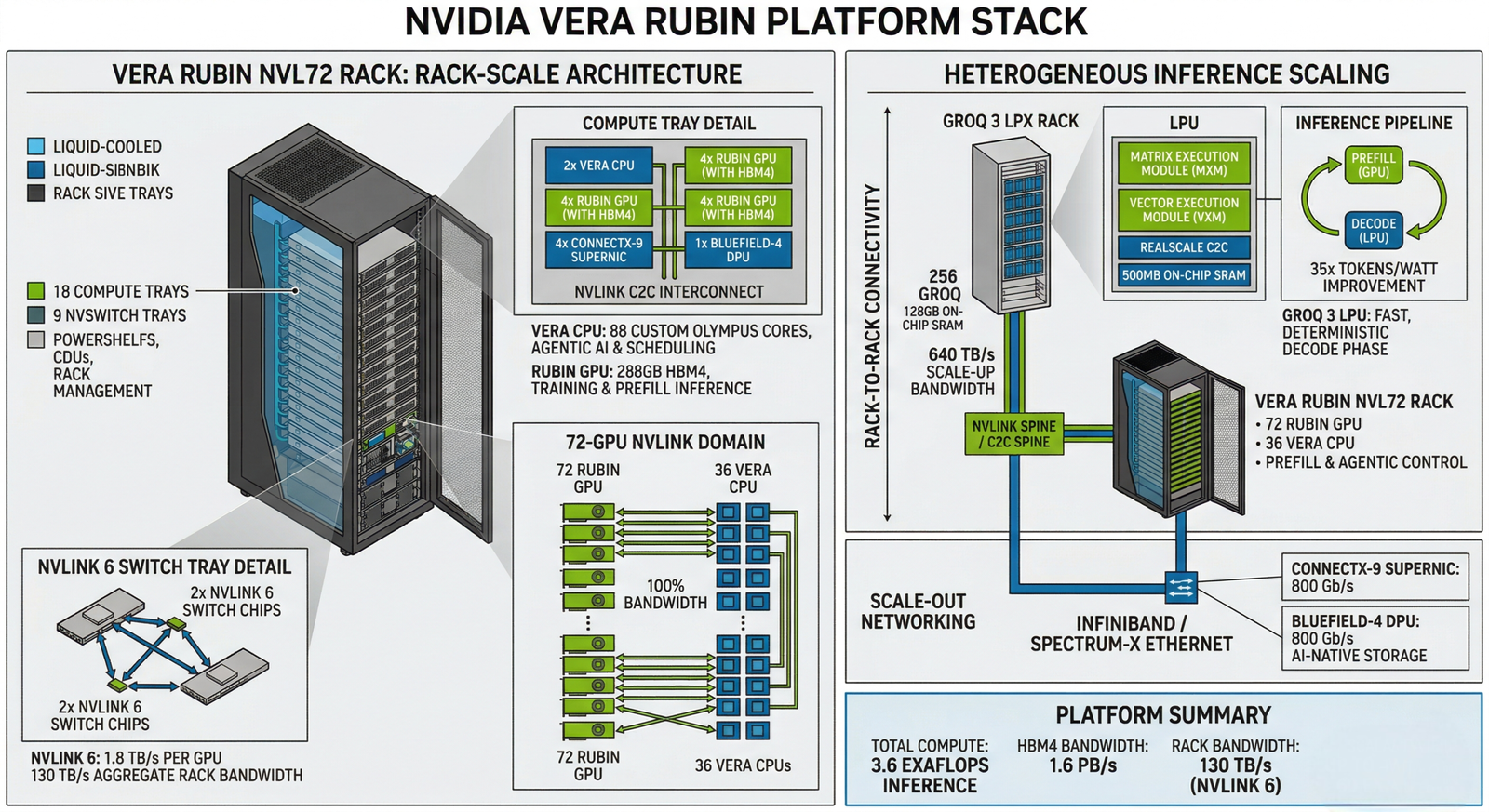
- [DIAGRAM: Vera Rubin platform stack — Vera CPU + Rubin GPU + NVLink 72 + Groq 3 LPU in rack-scale layout]
- The centre piece of GTC 2026 was the Vera Rubin platform NVIDIA’s successor to the Blackwell generation. Calling it “a new GPU,” though, would sell it short.
- Vera Rubin is not a single chip. It is a rack-scale supercomputer system made up of seven purpose built chips designed to work together as one machine. Jensen put it bluntly: “The chip is no longer the unit of compute.”
What’s Inside the Vera Rubin Platform?
| Component | Specification |
| Rubin GPU | 336 billion transistors, TSMC 3nm |
| Memory | 288GB HBM4, 22 TB/s bandwidth per GPU |
| Compute | 50 petaflops (NVFP4 precision) |
| Vera CPU | 88 custom Olympus cores, Armv9.2 |
| CPU Memory | Up to 1.5TB LPDDR5X |
| CPU-GPU Bandwidth | 1.8 TB/s via NVLink C2C |
| System Config | NVLink 72 – 72 GPUs acting as one supercomputer |
| Shipping | H2 2026 |
- The Rubin GPU carries 336 billion transistors a 1.6x jump over Blackwell with sixth generation HBM4 memory delivering 2.8x more bandwidth than the previous generation. In plain terms: it moves data much faster, which matters when running large AI models.
- The Vera CPU is a brand new custom processor with 88 cores. It coordinates work across all the GPUs, especially for AI tasks that need fast access to large memory.
What Does “40 million Times More Compute in 10 Years” Mean?
- Jensen made a headline claim: Vera Rubin delivers 40 million times more compute than NVIDIA’s GPUs from a decade ago. That is not a typo. Moore’s Law alone does not explain it. The gains come from better chips, faster memory, smarter interconnects, and purpose-built software all compounding together.
Performance Jump vs. Blackwell
- 2 – 3x better at lower inference tiers (everyday tasks, free tier queries)
- 35x better at high end inference tiers (complex reasoning, long documents)
- 10x better inference performance per watt
- That last number matters for businesses. Better performance per watt means lower electricity bills at scale.
Who’s Already Using It?
- Microsoft Azure confirmed it already runs the first Vera Rubin rack. Anthropic, Meta, Mistral AI, and OpenAI all confirmed plans to use Vera Rubin for frontier model training and inference.
What Comes After Vera Rubin?
- NVIDIA also previewed Vera Rubin Ultra, arriving in 2027. It introduces a new rack design called Kyber, which connects 144 GPUs in a single NVLink domain double the 72 in standard Vera Rubin. Compute trays slot in vertically, NVLink switches sit along the back wall. It is a denser, faster setup built for the next wave of agentic AI workloads.
- [INTERNAL: NVIDIA Blackwell architecture overview]
Groq 3 LPU: NVIDIA’s New Inference Chip Explained

- [IMAGE: Groq 3 LPU chip —alt: NVIDIA Groq 3 LPU inference chip GTC 2026]
- One of GTC 2026’s biggest surprises was not a GPU at all. Jensen unveiled the Groq 3 LPU a different type of AI chip built for one specific job: inference.
What Is “Inference” and Why Does It Need Its Own Chip?
- Training = Teaching an AI model. Expensive, one-time, requires massive compute.
- Inference = Using the trained model to answer questions. Happens billions of times a day.
- NVIDIA’s GPUs dominate training. But inference has different needs less about raw power, more about speed and efficiency at scale. That is where the Groq 3 LPU (Language Processing Unit) comes in.
The $20 Billion Acquisition Behind It
- In December 2025, NVIDIA completed a $20 billion asset purchase of Groq its largest deal ever. Groq was founded by engineers who originally built Google’s TPU. NVIDIA brought on key staff including co founder Jonathan Ross and president Sunny Madre, and just two months later, the Groq 3 LPU was already in production.
- That is a fast turnaround. And a sign of how seriously NVIDIA takes the inference market.
How Does the Groq 3 LPU Work with Vera Rubin?
- The Groq 3 LPU does not replace the GPU it works alongside it. NVIDIA’s Dynamo software splits the inference workload:
- Vera Rubin GPU handles the “prefill” phase reading and understanding the prompt
- Groq 3 LPU handles the “decode” phase generating the actual response
- The two chips run together through Dynamo, delivering 35x more throughput per megawatt compared to Blackwell GPUs running alone.
| Metric | Vera Rubin Alone | Vera Rubin + Groq 3 LPU |
| High-tier token speed | Baseline | Up to 35x faster |
| Power efficiency | 10x over Blackwell | Further improved |
| Use case | Training + inference | Optimized for fast inference |
- The Groq 3 LPX rack holds 256 LPUs and sits alongside Vera Rubin systems in data centers. Jensen confirmed improved LPX versions are already on the roadmap.
- Expected shipping: Q3 2026.
- [EXTERNAL: NVIDIA official Vera Rubin product page]
Feynman: A Look at NVIDIA’s 2028 GPU
- Jensen has a habit of announcing the chip after the one he just released. This year, he gave the first official preview of Feynman NVIDIA’s next platform targeting 2028.
What We Know About Feynman
| Component | Detail |
| Feynman GPU | 3D dies stacking (first in NVIDIA silicon) |
| Process Node | TSMC A16 1.6nm |
| CPU | Rosa (short for Rosalind) |
| LPU | LP40, co-developed with the Groq team |
| Networking | BlueField5, ConnectX10, Kyber rack with copper + CPO |
| Scale | NVL1152 8x the density of Vera Rubin Ultra |
- The 1.6nm process node deserves attention. Today’s cutting edge chips run at 3nm. Moving to 1.6nm packs more transistors into a smaller space better performance, lower power. This will be NVIDIA’s first chip in the sub 2nm class.
- 3D die stacking is another first. Instead of laying chip components side by side, they stack on top of each other, allowing faster connections between memory and compute.
- Jensen stayed deliberately vague on performance numbers “the generation I’m most excited to not say too much about yet” but the signal was clear: NVIDIA plans through 2028, and every generation stays fully backward-compatible with previous software.
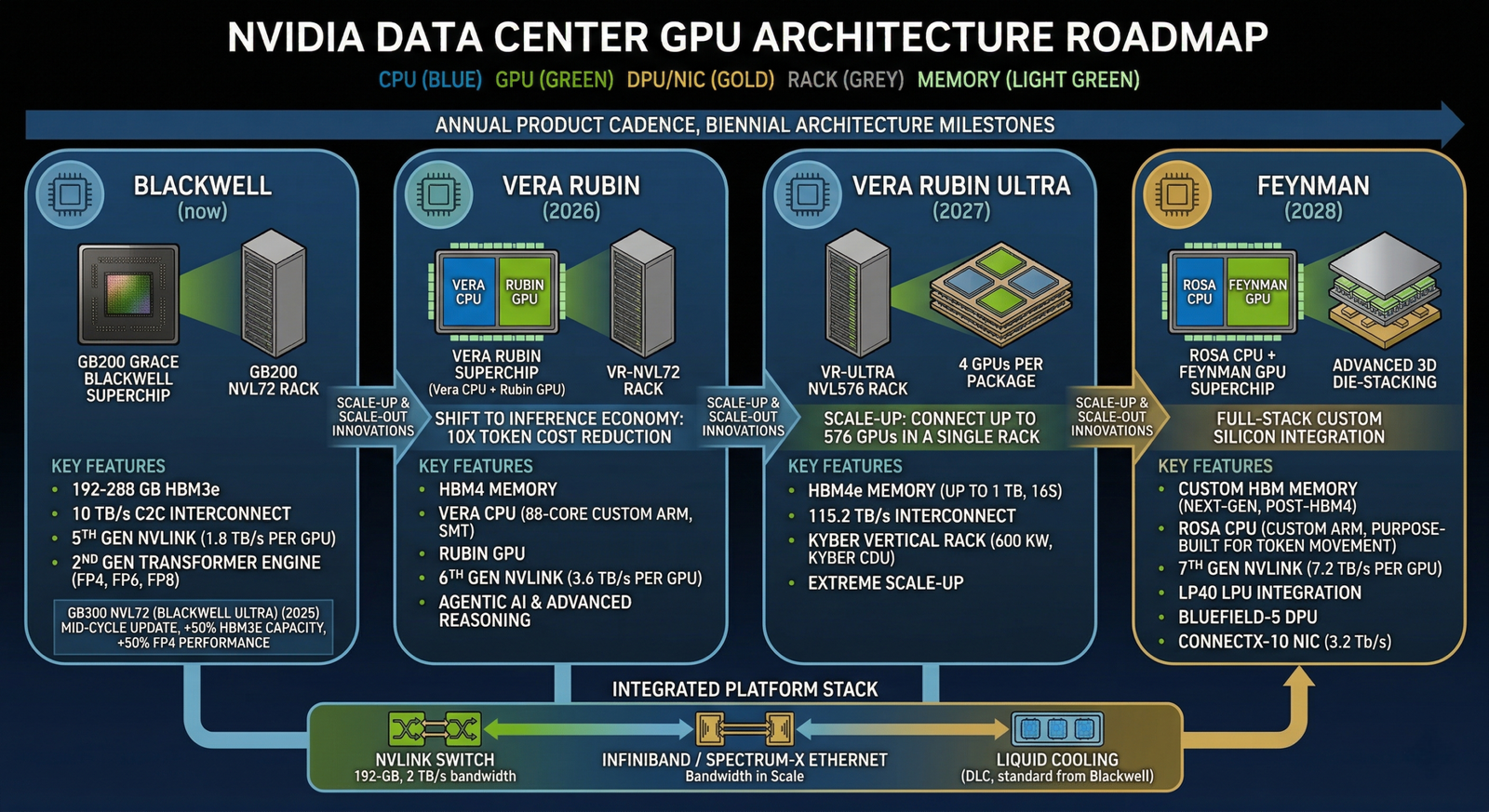
- [DIAGRAM: NVIDIA GPU roadmap — Blackwell (now) → Vera Rubin (2026) → Vera Rubin Ultra (2027) → Feynman (2028)]
DLSS 5: What It Means for PC Gaming


- [IMAGE: DLSS 5 gaming graphics comparison —alt: NVIDIA DLSS 5 neural rendering demo GTC 2026]
- Amid all the enterprise AI talk, Jensen saved a moment for gamers: DLSS 5, arriving later in 2026 as a driver update for current RTX 50-series cards.
What Is DLSS?
- DLSS stands for Deep Learning Super Sampling. It uses AI to make games look better and run faster at the same time. DLSS 4 already delivers solid results DLSS 5 pushes it further.
What’s New in DLSS 5?
- Jensen framed it directly: “25 years after NVIDIA invented the programmable shader, we are reinventing computer graphics once again. DLSS 5 is the GPT moment for graphics.”
- The key upgrade shifts from post-processing (AI cleaning up a rendered frame after the fact) to generative control at the geometry level the AI participates in how the image gets built from the ground up, not just how it gets polished at the end.
- In plain terms: instead of sharpening an already rendered frame, DLSS 5 uses generative AI to help construct parts of the visual in real time. The focus is on dramatic improvements to human faces and fine surface details.
- Important: DLSS 5 is a software update for existing RTX 50 series hardware. No new GPU required.
- Online reaction has been mixed. Some gamers praised the visual quality. Others raised concerns about an “AI-generated” feel to certain outputs. Jensen pushed back: “This is not post-processing at the frame level it’s generative control at the geometry level.”
- [INTERNAL: RTX 50 series GPU guide]
Agentic AI: NemoClaw, OpenClaw, and What Comes Next
- The most strategically significant announcement at GTC 2026 was not hardware. It was NVIDIA’s push into agentic AI and its partnership with OpenClaw.
What Is an “AI Agent”?
- An AI agent does not just answer questions it takes actions. It can browse the web, write and send emails, schedule meetings, run code, update databases, and complete multistep tasks without constant human input.
- Jensen put it plainly: “Every single company in the world now needs an OpenClaw strategy.”
What Is OpenClaw?
- OpenClaw is an opensource platform for building and deploying AI agents. It went viral in early 2026 after Austrian developer Peter Steinberger released it publicly. Developers can build custom AI agents that operate through apps like Telegram, and a large developer community formed quickly around it.
- Jensen compared OpenClaw to Linux calling it “the operating system for personal AI” and “the beginning of a new renaissance in software.”
What Is NemoClaw?
- NemoClaw is NVIDIA’s enterprise grade version of the OpenClaw framework. The name blends two things:
- Nemo NVIDIA’s enterprise AI platform
- Claw from OpenClaw
- NemoClaw lets companies deploy AI agents inside corporate networks without exposing proprietary data. Jensen described it as “an open-sourced operating system of agentic computers.”
New Frontier Model Coalition Nemotron
- NVIDIA also formed the Nemotron Coalition, a group of AI companies building open frontier models together. Members include Perplexity, Mistral AI, Black Forest Labs, Reflection AI, and Cohere.
- New models released at GTC 2026:
- Nemotron 3 language and reasoning model
- Cosmos 2 world simulation model for physical AI
- Groot 2 robotics foundation model
- Alpamayo autonomous vehicle AI model
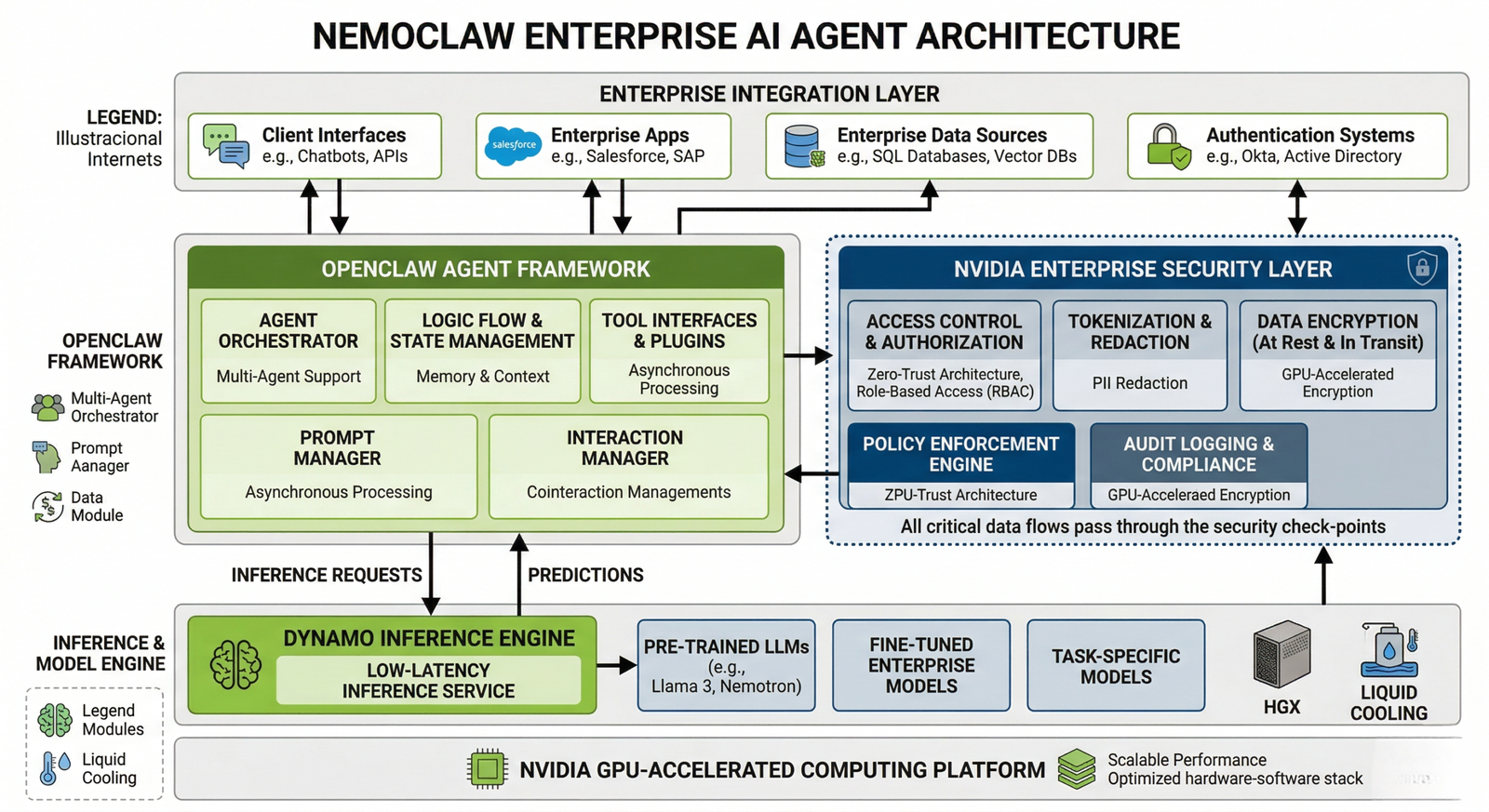
- [DIAGRAM: NemoClaw enterprise AI agent architecture OpenClaw framework + NVIDIA enterprise security layer + Dynamo inference]
- [INTERNAL: AI agents for enterprise guide]
Self Driving Cars and Robotics: The Physical AI Leap

- [IMAGE: NVIDIA autonomous vehicle demo — alt: NVIDIA Drive Hyperion self-driving car system GTC 2026]
“The ChatGPT Moment for Autonomous Driving Is Here”
- That was Jensen’s framing and he backed it with numbers. Four major automakers joined NVIDIA’s Drive Hyperion autonomous vehicle program at GTC 2026:
| Automaker | Output |
| BYD | Level 4 autonomous vehicles |
| Hyundai | Level 4 autonomous vehicles |
| Nissan | Level 4 autonomous vehicles |
| Geely | Level 4 autonomous vehicles |
- These four companies together produce roughly 18 million cars per year. Isuzu and China’s Tier IV are also building autonomous buses using NVIDIA’s AGX Thor chip. NVIDIA also announced a new partnership with Uber for autonomous ride-hailing deployment.
- What does “Level 4 autonomous” mean? The car drives itself without human input in most conditions no hands on the wheel required.
Robots Are Everywhere
- Jensen was direct: “I cannot think of a company building robots today that is not working with NVIDIA.”
- The GTC 2026 show floor featured 110 robots’ humanoid robots, robotic arms, autonomous mobile robots, and quadrupeds. Highlights included:
- Olaf from Frozen a Disney robot trained using NVIDIA’s Newton physics engine and Isaac Lab walked onstage with Jensen, demonstrating realistic movement and conversation. It runs on Jetson computer hardware.
- AGIBOT humanoid Trained using NVIDIA Isaac Sim and Isaac Lab for pick and place tasks
- Agile ONE A humanoid by Agile Robots, trained in simulation and demonstrated in the exhibit hall
- NVIDIA’s Groot 2 model is the foundation AI model for humanoid robots think of it as ChatGPT, but for robot brains. It trains in simulation using Isaac Lab and Omniverse, then deploys in physical robots.
Vera Rubin Space 1: AI in Orbit
- Jensen also revealed Vera Rubin Space 1 a radiation-hardened version of NVIDIA’s AI hardware built for satellites. It delivers 25x more compute than the space-rated H100 GPUs currently in use, opening the door to AI inference directly in orbit. Aerospace partnerships are already active.
- [EXTERNAL: NVIDIA Isaac robotics platform documentation]
The $1 Trillion Outlook: What Jensen’s Numbers Mean
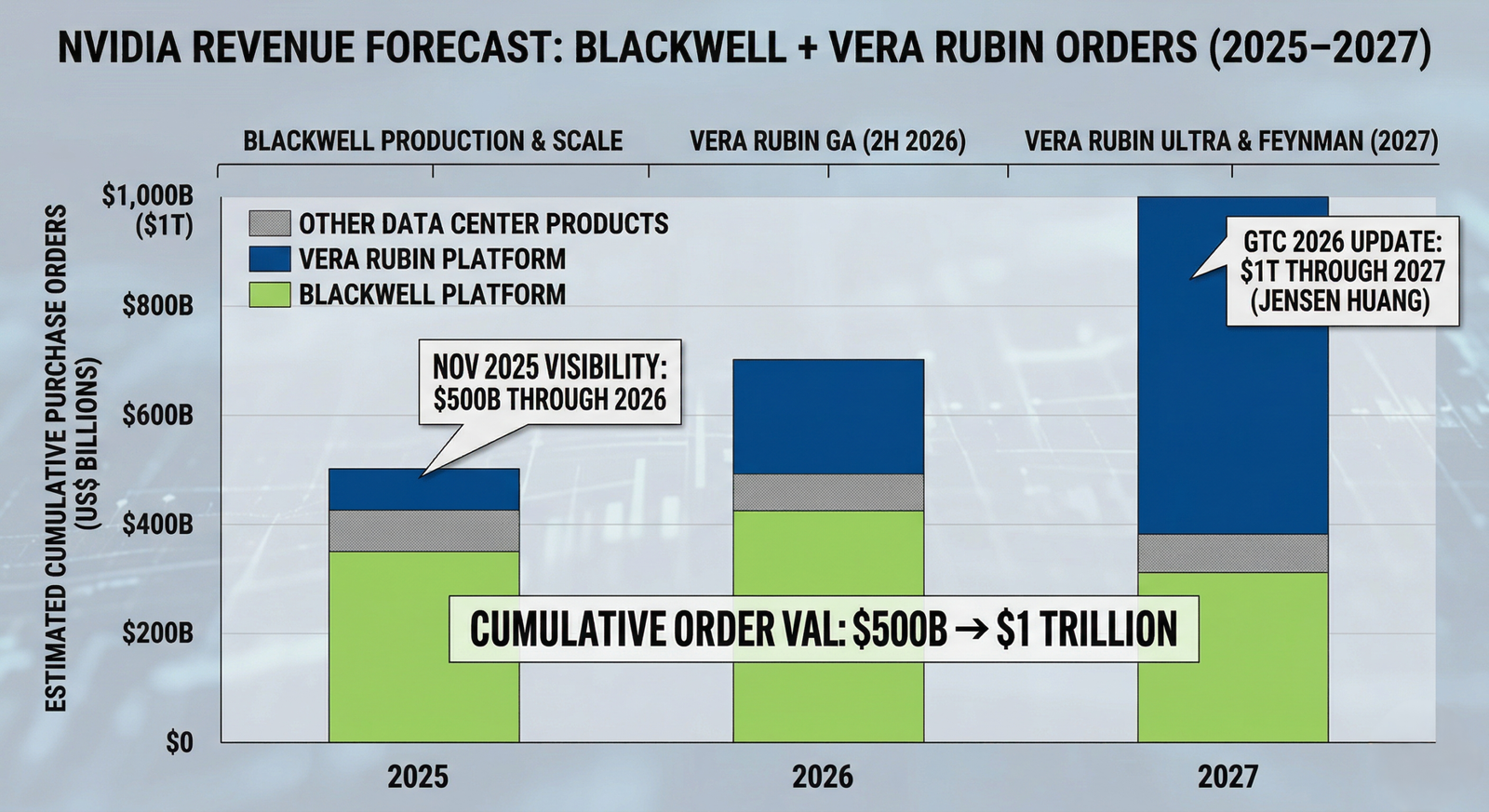
- [DIAGRAM: NVIDIA revenue forecast bar chart — Blackwell + Vera Rubin orders 2025→2027, $500B → $1T]
- Numbers flew fast at GTC 2026. Here is what the biggest ones mean.
$1 Trillion in Orders
- Jensen announced that purchase orders for Blackwell and Vera Rubin systems are on track to reach $1 trillion through 2027. Last fall, that number sat at $500 billion. It doubled in under six months.
- To put it in context: NVIDIA’s full year revenue for FY2026 was $215.9 billion. A $1 trillion order pipeline through 2027 means the growth curve has not flattened.
- Why is demand this high?
- AI model training still requires massive GPU clusters
- Inference is now the dominant AI workload and it grows exponentially as AI enters more products
- Agentic AI multiplies the compute needed, since agents run multi-step tasks continuously
Token Economy: AI as Workplace Infrastructure
- Jensen introduced a concept that got real attention: annual AI token budgets for engineers. Just as companies give employees’ salaries and software tools, Jensen argued engineers should now receive a dedicated budget of AI compute measured in tokens each year.
- His reasoning: engineers with token budgets can become 10x more productive. He positioned AI compute as essential workplace infrastructure, comparable to salaries, equity, and development tools.
- The token pricing NVIDIA outlined ranges from free tiers to premium plans running approximately $150 per million tokens.
7x Speed from Software Alone
- One of GTC’s more overlooked announcements: on the same Blackwell hardware, software updates alone improved token generation from 700 to 5,000 tokens per second a 7x gain. The race is not only about building new chips. Optimizing existing infrastructure delivers real results too.
- [INTERNAL: NVIDIA Blackwell Dynamo software overview]
FAQ
- What is NVIDIA GTC 2026? NVIDIA GTC 2026 is NVIDIA’s annual developer conference, held March 16 – 19, 2026, in San Jose, California. CEO Jensen Huang delivered a two hour keynote covering new AI chips (Vera Rubin), inference hardware (Groq 3 LPU), gaming tech (DLSS 5), agentic AI (NemoClaw), autonomous vehicles, robotics, and a $1 trillion AI demand forecast.
- What is the Vera Rubin chip? Vera Rubin is NVIDIA’s new AI computing platform not a single chip, but a system of 7 purpose-built chips and 5 rack types designed to work as one rack scale supercomputer. It features a Rubin GPU with 336 billion transistors, 288GB HBM4 memory, and 22 TB/s bandwidth. Systems begin shipping to cloud providers in H2 2026.
- What is the Groq 3 LPU and how is it different from a GPU? The Groq 3 LPU (Language Processing Unit) is a chip designed for AI inference the process of using a trained AI model to generate responses. Unlike GPUs built for parallel computation, LPUs optimize for low latency, high throughput token generation. Paired with Vera Rubin GPUs via NVIDIA Dynamo, the combination delivers up to 35x more throughput per megawatt.
- What is DLSS 5 and when does it release? DLSS 5 is NVIDIA’s next generation AI rendering technology for PC games. It uses generative AI to improve visuals at the geometry level not just post processing a finished frame. It arrives as a driver update for existing RTX 50 series cards in autumn 2026.
- What is NemoClaw? NemoClaw is NVIDIA’s enterprise grade AI agent platform, built on the open source OpenClaw framework. It lets companies deploy AI agents inside corporate networks without exposing private data. Jensen compared it to “an opensource operating system of agentic computers.”
- What is the Feynman GPU? Feynman is NVIDIA’s next generation GPU platform targeting 2028. It runs on TSMC’s 1.6nm A16 process, includes 3D die stacking for the first time in NVIDIA hardware, and pairs with a new Rosa CPU and LP40 LPU codeveloped with the Groq team. No performance numbers have been released yet.
Conclusion
- NVIDIA GTC 2026 confirmed one thing clearly: the company is no longer just a chip maker.
- From the Vera Rubin rack scale supercomputer to the Groq 3 LPU inference engine, from NemoClaw enterprise agents to Level 4 autonomous vehicles and robots walking onstage NVIDIA is going after every layer of the AI stack, from silicon to software to physical deployment.
- Quick recap of every major announcement:
- Vera Rubin 7 new chips, 5 racks, shipping H2 2026; 35x high tier inference gains
- Groq 3 LPU First chip from NVIDIA’s $20B acquisition; optimized for inference; ships Q3 2026
- Feynman 2028 roadmap preview; TSMC 1.6nm, 3D die stacking, Rosa CPU, LP40 LPU
- DLSS 5 Generative AI graphics upgrade for RTX 50 series; arrives autumn 2026
- NemoClaw Enterprise AI agent framework; compared to Linux for AI
- Autonomous vehicles BYD, Hyundai, Nissan, Geely building Level 4 cars; Uber partnership
- Robotics Groot 2 model, 110 robots on show floor, Disney Olaf demo
- $1 trillion demand signal Orders for Blackwell + Vera Rubin through 2027
- Whether you are a tech enthusiast, investor, developer, or just someone curious about where AI is headed GTC 2026 gave a clear answer: the infrastructure era is still picking up speed.
- Disclosure: This article is written for informational purposes. The author holds no financial positions in NVIDIA or any mentioned companies. All specifications are sourced from official NVIDIA announcements and verified industry reporting as of March 2026.
